In this post I’m going to look at the new feature of SQL Server’s 2019 Database Engine – Batch Mode on Row Store. I start with a quick introduction and then look at some curious details, that I have found playing with this feature so far. At the moment of writing this post I use the last public version of SQL Server – SQL 2019 CTP 2.0.
Introduction
When you run a query in SQL Server, the Query Processor plans, how it should actually get the desired result. This plan, expressed in a tree of fundamental building blocks (iterators) connected to each other is called a query plan. Each iterator with its properties represents a certain processing action applied to a portion of data, while the data flows through a tree of iterators, it gets transformed and finally we get a result.
Prior to SQL Server 2012 a unit of data transferred through a tree was a row. Then in SQL 2012 Microsoft introduced the first version of Columnstore (CS) indexes, indexes designed for analytical workloads. Analytical workloads used to work with millions and billions of rows. To execute a query that processes such a big amount of data more effectively, a new execution mode was designed – Batch Mode.
While in “classical” query processing a unit of data is row, in a new batch processing a unit of data is a batch of rows. Starting with SQL 2012 we have two query execution modes: Row Mode – regular execution mode, and Batch Mode – execution mode for analytical queries with CS indexes.
Batch Mode
A batch is a structure of 64 KBs, allocated for a bunch of rows, that contains column vectors and qualifying rows vector. Depending on the number of columns it may contain from 64 to 900 rows.
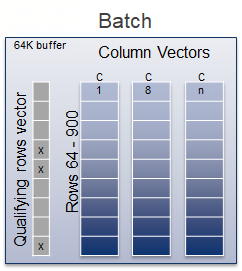
For example, if there is a scan in a batch mode with a predicate, a server may mark some bits in a qualifying rows vector of a batch structure to indicate these marked rows are excluded from the further processing, and then pass the structure’s pointer to the next batch iterator.
The main advantages of Batch Mode are:
- Algorithms optimized for the multi-core modern CPUs;
- Better CPU cache utilization and increased memory throughput;
- Reduced number of CPU instructions per processed row.
All these features make Batch Mode much faster than Row Mode (typically an order of magnitude, 10x-100x times faster) for analytical queries with CS indexes. One major condition for Batch Mode is a presence of a CS index. If you don’t have a CS index on a table involved in a query, you won’t get Batch Mode.
However, some analytical queries may benefit from Batch Mode without a CS index, or CS cannot be created due to some limitations.
There are a few tricks that allow you to enable Batch Mode on a Rowstore table for example with a dummy filtered CS index (see this post from Itzik Ben-Gan), but SQL Server 2019 may use Batch Mode on Rowstore without any extra efforts from your side.
Batch Mode on Row Store
To enable Batch Mode over Rowstore you should simply switch your DB to a latest compatibility level (CL), which is 150 in SQL Server 2019. I use AdventureworksDW2016CTP3 DB to demonstrate how it looks like in compare with previous CL 140 (SQL Server 2017).
use AdventureworksDW2016CTP3; go alter database AdventureworksDW2016CTP3 set compatibility_level = 140; go set statistics xml on; select count_big(*) from dbo.FactResellerSalesXL_PageCompressed; set statistics xml off; go alter database AdventureworksDW2016CTP3 set compatibility_level = 150; go set statistics xml on; select count_big(*) from dbo.FactResellerSalesXL_PageCompressed; set statistics xml off; go
You may see in the Properties of the Clustered Index Scan operator that under CL 140 the execution mode is Row Mode while under CL 150 it is Batch Mode. You can also see, if Batch Mode on Rowstore is used, the new property BatchModeOnRowStoreUsed appears in a query plan’s SELECT element.
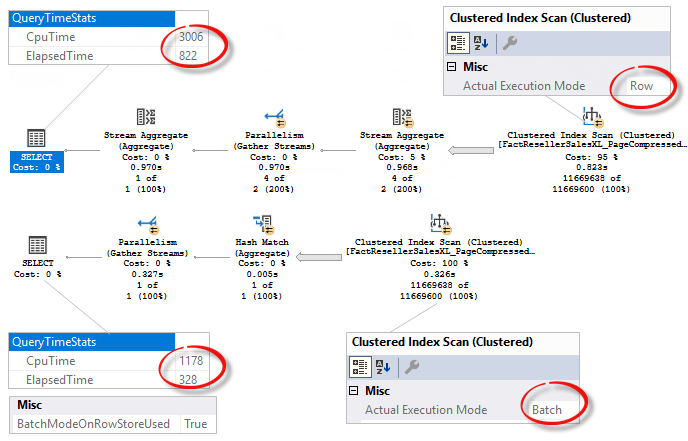
I ran these queries several times and on average Batch Mode is three times faster for this query.
Heuristics
In case of the presence of a CS index, SQL Server considers batch mode to be used every time. It is not necessary that it will choose Batch Mode, this is still a cost-based decision, but it will consider it.
If there is no CS index on a table SQL Server uses heuristics to determine, whether it will be beneficial to consider batch mode or not, as it is written in the documentation:
Even if a query does not involve any table with a columnstore index, the query processor now uses heuristics to decide whether to consider batch mode. The heuristics consist of:
- An initial check of table sizes, operators used, and estimated cardinalities in the input query.
- Additional checkpoints, as the optimizer discovers new, cheaper plans for the query. If these alternative plans do not make significant use of batch mode, the optimizer will stop exploring batch mode alternatives.
I decided to look more close at those heuristics using WinDbg and public debug symbols.
For that reason I took the query we have seen earlier with Batch Mode, put a break point on a method sqllang!BatchModeHeuristics::FVisitInputNode and ran the query. At some point stepping through the function we may see the following instructions:

What we see here is that a method CardGet (cardinality get) of a statistics object is called, value 41664210c0000000 is moved to xmm0 CPU register and then compared with a constant 4100000000000000. Depending on that comparison a server will choose either continue heuristic checks or not. If we use any hex to float converter (for example, I used this one), we may see that a first number converted to double is 11669600 which is a cardinality of a table FactResellerSalesXL_PageCompressed, and the second number is 131072, which is a “magical” (heuristic) constant inside SQL Server, that is used as a threshold for the decision about Batch Mode.
There are several other places where constants with the same value are checked, those are:
- Check for promising joins (binary and n-ary);
- Check for aggregates;
- Check for window aggregates.
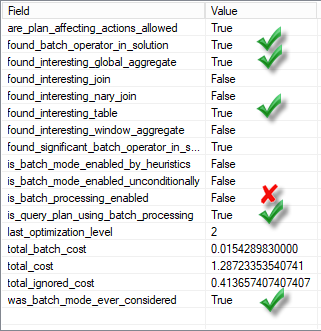
There is also an extended event batch_mode_heuristics, and we see some similar columns there, I’ll enlist some of them with their description.
- are_plan_affecting_actions_allowed – Are we allowed to enable or disable batch mode?
- found_batch_operator_in_solution – Is there a batch operator in the solution?
- found_interesting_global_aggregate – Did we find a promising GbAgg in the input expression?
- found_interesting_join – Did we find a promising binary join in the input expression?
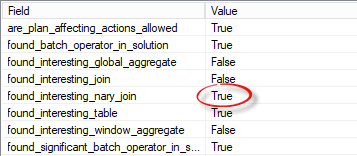
- found_interesting_nary_join – Did we find a promising n-ary join in the input expression?
- found_interesting_table – Did we find promising tables in the input expression?
- found_interesting_window_aggregate – Did we find a promising window aggregate in the input expression?
- found_significant_batch_operator_in_solution -This is when every other thing is true but you still don’t see batch-mode in the final plan, because the batch-operator did not cross the cost threshold to be considered for batch-mode.
- is_batch_mode_enabled_by_heuristics – Did we enable batch processing rules for this query using heuristics?
- is_batch_mode_enabled_unconditionally – Did we unconditionally enable batch processing rules?
- is_batch_processing_enabled – Is batch processing enabled?
- is_query_plan_using_batch_processing – Is the query plan using batch processing?
- last_optimization_level – Optimization level in which we might have turned off batch mode.
- total_batch_cost – Total cost of significant batch operators in the current solution.
- total_cost – Total cost of the current solution.
- total_ignored_cost – Total cost of operators we ignore.
- was_batch_mode_ever_considered – Was batch mode considered?
Let’s now create a session with this extended event and run some experiments.
At first, we’ll check the number 131072. We create one simple table of numbers with 131072 rows and then run two queries with a window aggregate. The first one use predicate “rn > 0” which selects all the numbers i.e. all 131072 rows, the second one use predicate “rn > 1”, which filters out one row.
use AdventureworksDW2016CTP3; go -- create table drop table if exists t_131072; create table t_131072 (rn bigint primary key); go -- fill the table with numbers from 1 to 131072 with cte as (select top(131072) rn = row_number() over(order by 1/0) from sys.all_columns c1, sys.all_columns c2) insert t_131072(rn) select rn from cte; go set showplan_xml on; go select sum(rn) over() from t_131072 where rn > 0; select sum(rn) over() from t_131072 where rn > 1; go set showplan_xml off; go drop table if exists t_131072;
You see that a difference in one row lead to a completely different plans, the first one use Batch Mode Window Aggregate operator because there are 131072 rows, the second one uses row mode and its regular plan shape for such type of queries with window aggregates, because 131071 is not enough to pass heuristic threshold.
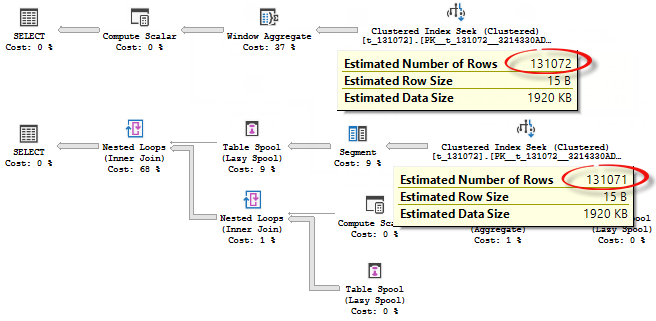
Now, let’s look at the extended events trace.
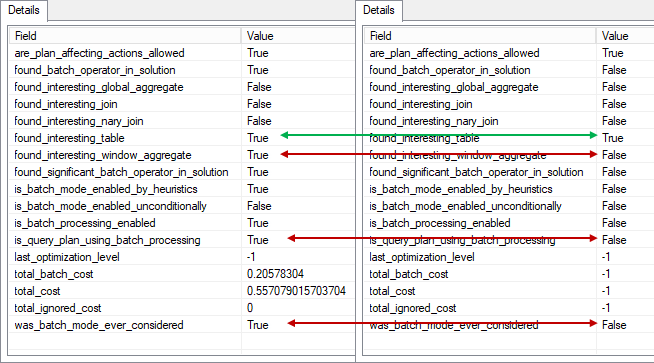
You may see that in the second query, even the table is considered to be “interesting” (it has at least 131072 rows), the window aggregate is not considered to be interesting because it has less then 131072 rows.
The same goes for aggregates. I use a subquery (select 1), to prevent a trivial plan, because batch mode is not considered for trivial plans.
select count_big(*), (select 1) from t_131072 where rn > 0; select count_big(*), (select 1) from t_131072 where rn > 1;
You may see that the first plan uses Batch Mode on Rowstore, while the second does not.
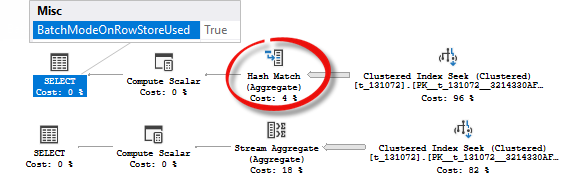
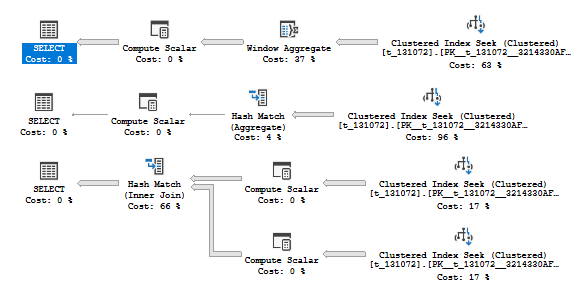
Now look at the joins. I use almost the same approach with a predicate, I also use an expression over a join predicate (adding 1) to avoid transitivity and to be able to manage join’s inputs cardinality independently.
The first query has two join inputs, 131072 rows each. The second has one 131071 and one 131072. The third one has both equal to 131071 rows.
select * from t_131072 t1 join t_131072 t2 on t1.rn+1 = t2.rn+1 where t1.rn > 0 and t2.rn > 0; -- 131072 and 131072 select * from t_131072 t1 join t_131072 t2 on t1.rn+1 = t2.rn+1 where t1.rn > 1 and t2.rn > 0; -- 131071 and 131072 select * from t_131072 t1 join t_131072 t2 on t1.rn+1 = t2.rn+1 where t1.rn > 1 and t2.rn > 1; -- 131071 and 131071
Although the plan shapes are the same, you may notice that two first queries are cheaper than the third one, which is because they are going to use batch mode.
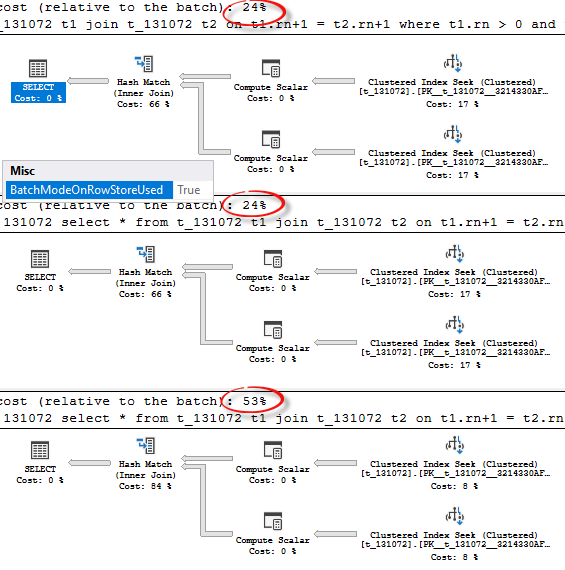
From that we may conclude, that at least one of the join’s input should be not less than 131072 rows.
If we expand the same approach to more than two joins we’ll see the following behavior, consider the example.
select * from t_131072 t1 join t_131072 t2 on t1.rn+1 = t2.rn+1 join t_131072 t3 on t1.rn+1 = t3.rn+1 where t1.rn > 1 and t2.rn > 1;
We added one more table t3, notice that it has no predicate on it, but tables t1 and t2 are still restricted with predicates. If we join (t1 and t2) first, both inputs are 131071 which is not enough to pass the threshold, so we should not use Batch Mode. If we join (t1 and t3) first at least one input is enough to pass heuristic threshold.
In this case SQL Server uses a concept of N-ary logical join, like it has a join operator that consumes multiple inputs at once. In this case, again if one input of this join is more or equal 131072, all the related iterators will consider to use Batch Mode.
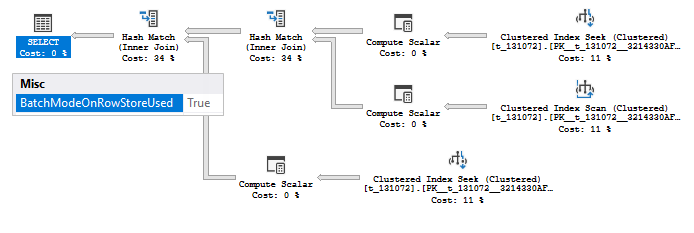
You will see a column found_interesting_nary_join in the extended event set to true as well.
To sum it all up, the heuristic rule for considering a Batch Mode on Row Store is:
- At least one table not less than 131072 rows;
- At least one potentially efficient batch operators: join, aggregate or window aggregate;
- At least one of the batch operator’s input should have not less than 131072 rows;
I’m not sure if this is a complete list, but this is what I have found so far.
Disclaimer.
I encourage you not to fix on the specific numbers, as they are not documented and are a subject to change without any note. I may even suppose, that after some time the new threshold values may start looking more promising or adequate and Microsoft change them. It is better to keep in mind the common principles, for example that some heuristics are based on cardinality.
Overriding Heuristics
There is an undocumented hint that overrides heuristics: OVERRIDE_BATCH_MODE_HEURISTICS.
If you take all the previous queries with a predicate rn > 1 that produced a Row Mode plan, add this hint and look at the new plans, you will see that they are now in Batch Mode.
select sum(rn) over() from t_131072 where rn > 1
option(use hint('OVERRIDE_BATCH_MODE_HEURISTICS'));
select count_big(*), (select 1) from t_131072 where rn > 1
option(use hint('OVERRIDE_BATCH_MODE_HEURISTICS'));
select * from t_131072 t1 join t_131072 t2 on t1.rn+1 = t2.rn+1 where t1.rn > 1 and t2.rn > 1
option(use hint('OVERRIDE_BATCH_MODE_HEURISTICS'));
The plans are now in Batch Mode.
This hint also removes a restriction for a table cardinality, so you may use a table less than 131072 rows. Even this query runs in Batch Mode (except a Constant Scan operator):

But it is important to note, that this hint is not forcing Batch Mode. You still need a “batch worth” operation and it is still a cost-based decision.
Cost
Return back to our table with 131072 rows and look at the plan of the following query.
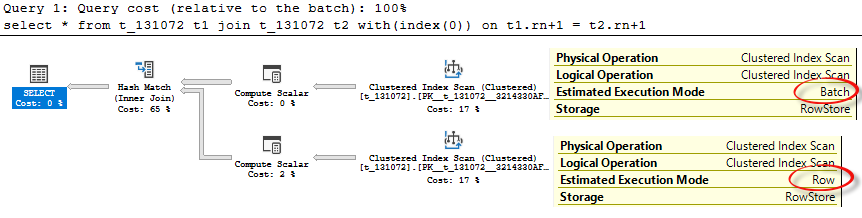
select * from t_131072 t1 join t_131072 t2 on t1.rn = t2.rn where t1.rn > 0;
It has a plan in Row Mode with a Merge Join, that runs only in Row Mode, however, we have enough rows (131072 rows) to consider Batch Mode.
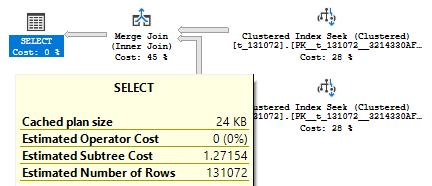
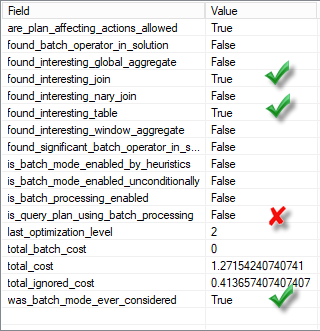
If we look at the extended events trace we may see that a server has found join to be interesting (inputs not less than 131072 rows as discussed earlier), found an interesting table even considered Batch Mode but not using it.
Let’s make a query more “analytical” by adding an aggregate.
select count(*) from t_131072 t1 join t_131072 t2 on t1.rn = t2.rn where t1.rn > 0;
We still don’t get Batch Mode on Row Store, even we have Batch Mode operator (Hash Match) in our query plan.
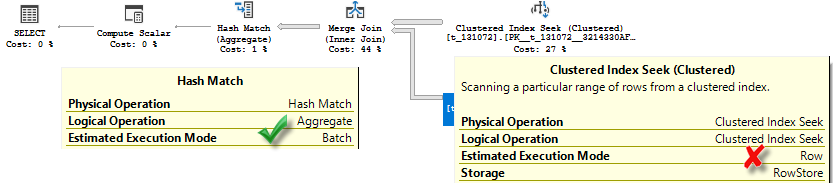
In the extended event we see that a query plan is using batch mode, but still no batch processing on Rowstore.
The reason for that is cost.
SQL Server optimizer is cost based and picks the cheapest plan alternative found so far. When it looks for the alternatives it does not explore all of them, it prunes out potentially expensive alternatives not to waste time and resources. The documentation says:
If these alternative plans do not make significant use of batch mode, the optimizer will stop exploring batch mode alternatives.
This is the case.
From the extended event columns description: last_optimization_level – Optimization level in which we might have turned off batch mode.

In our case last_optimization_level tells us that at the optimization stage number 2 (called “search 1” which is a little bit misleading) the optimizer has stopped exploring batch mode alternatives. This is because we have a single column table with a primary key on it and joining it with itself on this key. The merge join is the best alternative for that. But the merge join runs only in row mode, so the optimizer chooses, between running a query in batch mode with a hash join or in row mode with a merge join. In this case the last one is cheaper and was picked up into a query plan.
We may restrict our plan with a hash join only by adding an option (hash join) at the end of the query and see that a cost of hash join plan with batch mode (1.83885) is higher than a merge join plan with row mode (1.28723).
Costing is a mathematical model and sometimes it may miss real life situation, Batch Mode on Rowstore is based on costing and not an exception, also sometimes there might be issues related to a search path, it is useful to keep this in mind.
Controlling Batch Mode on Row Store
There are several ways you can control batch mode on rowstore behavior.
- Compatibility Level – Batch Mode on Row Store is enabled by default when you switch to the CL 150, either for the whole DB or using a query hint QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_150 in a USE HINT
- Scoped Configuration Option – BATCH_MODE_ON_ROWSTORE option may be used like ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = ON|OFF; to control batch mode on Rowstore on a database level.
- Hints ALLOW_BATCH_MODE and DISALLOW_BATCH_MODE – used in a USE HINT clause to allow or not allow batch mode on a query level. In this case, be careful, as it disallows batch mode for the query in general, not only for a Batch Mode on Row Store e.g. Scan, but the other operators also, and even for queries with Columnstore indexes.
- OVERRIDE_BATCH_MODE_HEURISTICS (undocumented) – overrides heuristics for a decision whether to consider Batch Mode on Rowstore or not.
- TF 11080 (undocumented) – turns off batch mode on row store, but does not restrict in general, similar to what does a scoped configuration option BATCH_MODE_ON_ROWSTORE, might be used on a query level for experiments.
- Hint WITH(INDEX(0)) (undocumented behavior) – though the hint itself is documented, the behavior in case of a batch mode on Rowstore is not documented. Applying this hint on a clustered index or heap will lead to an unordered scan and this scan will be done in Row Mode. Make sure you don’t need an ordered scan and keep in mind that it is not documented in the case of Batch Mode on Row Store. Below you may see an example with a plan.
Now we may drop the test table.
drop table if exists t_131072;
Batch Mode Rowstore Scan
Prior to SQL Server 2019 there were some hacks to enable a batch mode without having an actual Columnstore index. I mentioned one of them earlier in this post – creating a dummy CS filtered index.
To compare the differences between Batch Mode Rowstore Scan and Batch Mode Rowstore Scan with Columnstore Index I created two test tables, 1 000 000 rows each and a unique clustered index. On the second table I created a dummy CS index.
use AdventureworksDW2016CTP3; go drop table if exists FactResellerSalesXL, FactResellerSalesXL_dummy; -- Create two tables with the same data select top(1000000) * into FactResellerSalesXL from FactResellerSalesXL_PageCompressed; select * into FactResellerSalesXL_dummy from FactResellerSalesXL; create unique clustered index cix on FactResellerSalesXL(SalesOrderNumber, SalesOrderLineNumber); create unique clustered index cix on FactResellerSalesXL_dummy(SalesOrderNumber, SalesOrderLineNumber); -- Create a dummy CS index with an impossible condition create nonclustered columnstore index ix_dummy ON dbo.FactResellerSalesXL_dummy(ProductKey) where ProductKey = -1 and ProductKey = -2; go
Now we issue a query that should use batch mode. To avoid side effect of mixing the batch mode reasons: either consider Batch Mode by heuristics or unconditionally because of CS index – we’ll disable batch mode for row store globally and enable it with a hint. We also restrict parallelism for simplicity with a hint MAXDOP and turn on the undocumented TF 8607, that will show us the physical operators tree output for both queries.
alter database scoped configuration set BATCH_MODE_ON_ROWSTORE = off;
go
set showplan_xml on;
go
select count_big(*) from FactResellerSalesXL
option(maxdop 1, querytraceon 3604, querytraceon 8607, use hint('ALLOW_BATCH_MODE'));
select count_big(*) from FactResellerSalesXL_dummy
option(maxdop 1, querytraceon 3604, querytraceon 8607);
go
set showplan_xml off;
go
alter database scoped configuration set BATCH_MODE_ON_ROWSTORE = on;
For both queries the Hash Match aggregation operator is done in Batch Mode, however, for the first query batches come directly from the Scan operator and for the second query the Scan works in a Row Mode and there is an invisible RowToBatch adapter that transfers rows to batches.
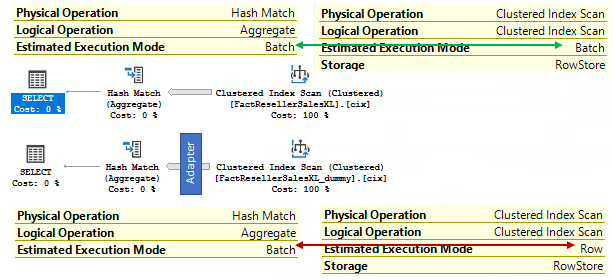
If we switch to the message tab of SSMS we will see the Adapter operator in the output tree of physical operators.
*** Output Tree: *** PhyOp_ExecutionModeAdapter(BatchToRow) PhyOp_HashGbAgg(batch) Eager Distinct PhyOp_Range TBL: FactResellerSalesXL(1)... ... *** Output Tree: *** PhyOp_ExecutionModeAdapter(BatchToRow) PhyOp_HashGbAgg(batch) Eager Distinct <strong>PhyOp_ExecutionModeAdapter(RowToBatch)</strong> PhyOp_Range TBL: FactResellerSalesXL_dummy(1)...
At the lower level of DB engine, the first query gets rows with the help of CBpQScanRowStoreScan class object. Below you see a WinDbg callstack for the first query.
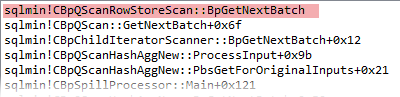
The second one uses traditional CQScanTableScanNew class object to get rows and then passes them to a CBpQScanAdapter class object for conversion.
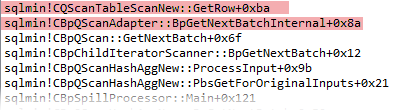
I couldn’t find any performance difference between these two queries in a single execution, probably the table is too small and both are very fast, so I ran a few tests with multiple executions commenting the first query or the second one.
alter database scoped configuration set BATCH_MODE_ON_ROWSTORE = off;
go
set nocount on;
declare @c bigint, @i int = 1, @d datetime = getdate();
while @i <= 100 begin
--select @c = count_big(*) from FactResellerSalesXL option(maxdop 1, use hint('ALLOW_BATCH_MODE'));
select @c = count_big(*) from FactResellerSalesXL_dummy option(maxdop 1);
set @i+=1;
end;
print datediff(ms, @d, getdate());
go 3
alter database scoped configuration set BATCH_MODE_ON_ROWSTORE = on;
go
For the query first query I got on average 30-40 seconds on my machine. The result of one of the test runs:
Beginning execution loop 38894 31690 42343 Batch execution completed 3 times.
For the second query I got on average 50-60 seconds, one of the test runs:
Beginning execution loop 61013 58760 62303 Batch execution completed 3 times.
Converting data to a batch format at the lower level with a CBpQScanRowStoreScan is about 30-40% faster than reading data, passing it to an adapter and converting there. This makes sense as we save CPU cycles avoiding extra operators in a query executable plan.
Interestingly, the cost for the first query is slightly higher 21.1829 vs 21.1385.
Bitmap filtering
One more thing that makes Batch Mode Rowstore Scan more effective than a Scan with CS over Rowstore is a bitmap filter support. Consider the following example. Again, the first query is using the new approach, the second one is using the old one with a dummy CS.
alter database scoped configuration set BATCH_MODE_ON_ROWSTORE = off;
go
set statistics xml on;
-- 1. Batch Mode On Row Store
select count_big(*)
from
dbo.FactResellerSalesXL f
join dbo.DimCurrency c on c.CurrencyKey = f.CurrencyKey
where
c.CurrencyAlternateKey like 'A%'
option(maxdop 1, use hint('ALLOW_BATCH_MODE'));
-- 2. Batch Mode for CS over Rowstore
select count_big(*)
from
dbo.FactResellerSalesXL_dummy f
join dbo.DimCurrency c on c.CurrencyKey = f.CurrencyKey
where
c.CurrencyAlternateKey like 'A%'
option(maxdop 1);
set statistics xml on;
go
alter database scoped configuration set BATCH_MODE_ON_ROWSTORE = on;
go
You may see the difference in query plans.
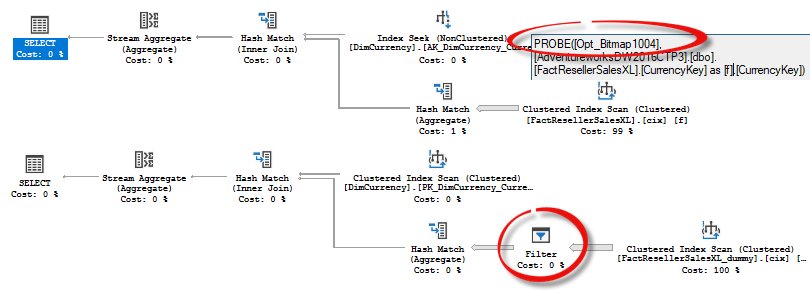
The first one uses a bitmap filter created by a Hash Join inside the Scan operator, it effectively filters out about 90% of rows, which is a good thing, because it reduces the number of rows to be processed further. The second one also has a bitmap filter, but as a separate operator, working in a Row Mode and the Scan returns the whole table.
Unfortunately, the bitmap filter is not pushed down to the batch mode scan over Rowstore if you join on string columns.
Conclusion
I see a great potential of a batch mode over Rowstore data, but I hope the optimizer will do it carefully and heuristics together with costing model will do their job well. The reason here is that a search space for the optimization changes significantly and the queries that previously got optimized in one way might be optimized differently now. This feature potentially may affect much more queries now than it was earlier with Batch Mode, because a Columnstore restriction has gone. We’ll see how it goes.
Thank you for reading.